Use data analysis methods to analyse the data
Collecting and using archival tool box needs your contribution can help change n training teaching core how to collect your data and analyze it, figuring out what it means, so that you can use it to draw some conclusions about your do we mean by collecting data? Now it’s time to collect your data and analyze it – figuring out what it means – so that you can use it to draw some conclusions about your work. In this section, we’ll examine how to do just do we mean by collecting data? You’ve decided how you’re going to get information – whether by direct observation, interviews, surveys, experiments and testing, or other methods – and now you and/or other observers have to implement your plan. You’ll have to record the observations in appropriate ways and organize them so they’re optimally ing and organizing data may take different forms, depending on the kind of information you’re collecting. The way you collect your data should relate to how you’re planning to analyze and use it. Regardless of what method you decide to use, recording should be done concurrent with data collection if possible, or soon afterwards, so that nothing gets lost and memory doesn’t of the things you might do with the information you collect include:Gathering together information from all sources and photocopies of all recording forms, records, audio or video recordings, and any other collected materials, to guard against loss, accidental erasure, or other ng narratives, numbers, and other information into a computer program, where they can be arranged and/or worked on in various ming any mathematical or similar operations needed to get quantitative information ready for analysis. These might, for instance, include entering numerical observations into a chart, table, or spreadsheet, or figuring the mean (average), median (midpoint), and/or mode (most frequently occurring) of a set of ribing (making an exact, word-for-word text version of) the contents of audio or video data (translating data, particularly qualitative data that isn’t expressed in numbers, into a form that allows it to be processed by a specific software program or subjected to statistical analysis). A smoking cessation program, for example, is an independent variable that may change group members’ smoking behavior, the primary dependent do we mean by analyzing data? The point, in terms of your evaluation, is to get an accurate assessment in order to better understand your work and its effects on those you’re concerned with, or in order to better understand the overall are two kinds of data you’re apt to be working with, although not all evaluations will necessarily include both. Quantitative data refer to the information that is collected as, or can be translated into, numbers, which can then be displayed and analyzed mathematically. As you might expect, quantitative and qualitative information needs to be analyzed tative data are typically collected directly as numbers. Can also be collected in forms other than numbers, and turned into quantitative data for analysis. Whether or not this kind of translation is necessary or useful depends on the nature of what you’re observing and on the kinds of questions your evaluation is meant to tative data is usually subjected to statistical procedures such as calculating the mean or average number of times an event or behavior occurs (per day, month, year). These operations, because numbers are “hard” data and not interpretation, can give definitive, or nearly definitive, answers to different questions. Various kinds of quantitative analysis can indicate changes in a dependent variable related to – frequency, duration, timing (when particular things happen), intensity, level, etc. And they can identify relationships among different variables, which may or may not mean that one causes numbers or “hard data,” qualitative information tends to be “soft,” meaning it can’t always be reduced to something definite. And that interpretation may be far more valuable in helping that student succeed than knowing her grade or numerical score on the ative data can sometimes be changed into numbers, usually by counting the number of times specific things occur in the course of observations or interviews, or by assigning numbers or ratings to dimensions (e. Where one person might see a change in program he considers important another may omit it due to perceived ative data can sometimes tell you things that quantitative data can’t. It may reveal why certain methods are working or not working, whether part of what you’re doing conflicts with participants’ culture, what participants see as important, etc. It may also show you patterns – in behavior, physical or social environment, or other factors – that the numbers in your quantitative data don’t, and occasionally even identify variables that researchers weren’t aware is often helpful to collect both quantitative and qualitative tative analysis is considered to be objective – without any human bias attached to it – because it depends on the comparison of numbers according to mathematical computations. Analysis of qualitative data is generally accomplished by methods more subjective – dependent on people’s opinions, knowledge, assumptions, and inferences (and therefore biases) – than that of quantitative data. Be aware, however, that quantitative analysis is influenced by a number of subjective factors as well. What the researcher chooses to measure, the accuracy of the observations, and the way the research is structured to ask only particular questions can all influence the results, as can the researcher’s understanding and interpretation of the subsequent should you collect and analyze data for your evaluation? This data collection and sensemaking is critical to an initiative and its future success, and has a number of data can show whether there was any significant change in the dependent variable(s) you hoped to influence.
Methods used to analyse data
Collecting and analyzing data helps you see whether your intervention brought about the desired term “significance” has a specific meaning when you’re discussing statistics. The level of significance is built into the statistical formulas: once you get a mathematical result, a table (or the software you’re using) will tell you the level of , if data analysis finds that the independent variable (the intervention) influenced the dependent variable at the . Data analyses may help discover unexpected influences; for instance, that the effort was twice as large for those participants who also were a part of a support group. By combining quantitative and qualitative analysis, you can often determine not only what worked or didn’t, but why. The effect of cultural issues, how well methods are used, the appropriateness of your approach for the population – these as well as other factors that influence success can be highlighted by careful data collection and analysis. Being a good trustee or steward of community investment includes regular review of data regarding progress and can show the field what you’re learning, and thus pave the way for others to implement successful methods and approaches. In that way, you’ll be helping to improve community efforts and, ultimately, quality of life for people who and by whom should data be collected and analyzed? Far as data collection goes, the “when” part of this question is relatively simple: data collection should start no later than when you begin your work – or before you begin in order to establish a baseline or starting point – and continue throughout. Ideally, you should collect data for a period of time before you start your program or intervention in order to determine if there are any trends in the data before the onset of the intervention. Additionally, in order to gauge your program’s longer-term effects, you should collect follow-up data for a period of time following the conclusion of the timing of analysis can be looked at in at least two ways: one is that it’s best to analyze your information when you’ve collected all of it, so you can look at it as a whole. Both approaches are legitimate, but ongoing data collection and review can particularly lead to improvements in your “who” question can be more complex. That’s not the case, you have some choices:You can hire or find a volunteer outside evaluator, such as from a nearby college or university, to take care of data collection and/or analysis for can conduct a less formal evaluation. Can collect the data and then send it off to someone – a university program, a friendly statistician or researcher, or someone you hire – to process it for can collect and rely largely on qualitative data. You wouldn’t want to conduct a formal evaluation of effectiveness of a new medication using only qualitative data, but you might be able to draw some reasonable conclusions about use or compliance patterns from qualitative possible, use a randomized or closely matched control group for comparison. By the same token, if 72% of your students passed and 70% of the control group did as well, it seems pretty clear that your instruction had essentially no effect, if the groups were starting from approximately the same should actually collect and analyze data also depends on the form of your evaluation. If you’re doing a participatory evaluation, much of the data collection - and analyzing - will be done by community members or program participants themselves. If you’re conducting an evaluation in which the observation is specialized, the data collectors may be staff members, professionals, highly trained volunteers, or others with specific skills or training (graduate students, for example). Another way analysis can be accomplished is by professionals or other trained individuals, depending upon the nature of the data to be analyzed, the methods of analysis, and the level of sophistication aimed at in the do you collect and analyze data? Your evaluation includes formal or informal research procedures, you’ll still have to collect and analyze data, and there are some basic steps you can take to do ent your measurement 've previously discussed designing an observational system to gather information. The definition and description should be clear enough to enable observers to agree on what they’re observing and reliably record data in the same and train observers. This may include reviewing archival material; conducting interviews, surveys, or focus groups; engaging in direct observation; data in the agreed-upon ways. Audio or video, journals, ze the data you’ve you do this depends on what you’re planning to do with it, and on what you’re interested any necessary data into the computer. Into a word processing program, or entering various kinds of information (possibly including audio and video) into a database, spreadsheet, a gis (geographic information systems) program, or some other type of software or ribe any audio- or videotapes. This may include sorting by category of observation, by event, by place, by individual, by group, by the time of observation, or by a combination or some other possible, necessary, and appropriate, transform qualitative into quantitative data. This might involve, for example, counting the number of times specific issues were mentioned in interviews, or how often certain behaviors were t data graphing, visual inspection, statistical analysis, or other operations on the data as ’ve referred several times to statistical procedures that you can apply to quantitative data.

If you have the right numbers, you can find out a great deal about whether your program is causing or contributing to change and improvement, what that change is, whether there are any expected or unexpected connections among variables, how your group compares to another you’re measuring, are other excellent possibilities for analysis besides statistical procedures, however. Journals can be particularly revealing in this area because they record people’s experiences and reflections over g patterns in qualitative data. In some cases, you may need to subject them to statistical procedures (regression analysis, for example) to see if, in fact, they’re random, or if they constitute actual s important findings. Whether as a result of statistical analysis, or of examination of your data and application of logic, some findings may stand out. It might be obvious from your data collection, for instance, that, while violence or roadway injuries may not be seen as a problem citywide, they are much higher in one or more particular areas, or that the rates of diabetes are markedly higher for particular groups or those living in areas with greater disparities of income. If you have the resources, it’s wise to look at the results of your research in a number of different ways, both to find out how to improve your program, and to learn what else you might do to affect the ret the you’ve organized your results and run them through whatever statistical or other analysis you’ve planned for, it’s time to figure out what they mean for your evaluation. Statistics or other analysis showed clear positive effects at a high level of significance for the people in your program and – if you used a multiple-group design – none, or far fewer, of the same effects for a similar control group and/or for a group that received a different intervention with the same purpose. As with programs with positive effects, these might be positive, neutral, or negative; single or multiple; or consistent or your analysis gives you a clear indication that what you’re doing is accomplishing your purposes, interpretation is relatively simple: you should keep doing it, while trying out ways to make it even more effective, or while aiming at other related issues as we discuss elsewhere in the community tool box, good programs are dynamic -- constantly striving to improve, rather than assuming that what they’re doing is as good as it can your analysis shows that your program is ineffective or negative, however – or, for that matter, if a positive analysis leaves you wondering how to make your successful efforts still more successful – interpretation becomes more complex. Correlations may also indicate patterns in your data, or may lead to an unexpected way of looking at the issue you’re can often use qualitative data to understand the meaning of an intervention, and people’s reactions to the observation that participants are continually suffering from a variety of health problems may be traced, through qualitative data, to nutrition problems (due either to poverty or ignorance) or to lack of access to health services, or to cultural restrictions (some muslim women may be unwilling – or unable because of family prohibition – to accept care and treatment from male doctors, for example). You have organized your data, both statistical results and anything that can’t be analyzed statistically need to be analyzed logically. Those are often matters for logical analysis, or critical ing and interpreting the data you’ve collected brings you, in a sense, back to the beginning. You have to keep up the process to ensure that you’re doing the best work you can and encouraging changes in individuals, systems, and policies that make for a better and healthier have to become a cultural detective to understand your initiative, and, in some ways, every evaluation is an anthropological heart of evaluation research is gathering information about the program or intervention you’re evaluating and analyzing it to determine what it tells you about the effectiveness of what you’re doing, as well as about how you can maintain and improve that ting quantitative data – information expressed in numbers – and subjecting it to a visual inspection or formal statistical analysis can tell you whether your work is having the desired effect, and may be able to tell you why or why not as well. It can also highlight connections (correlations) among variables, and call attention to factors you may not have ting and analyzing qualitative data – interviews, descriptions of environmental factors, or events, and circumstances – can provide insight into how participants experience the issue you’re addressing, what barriers and advantages they experience, and what you might change or add to improve what you you’ve gained the knowledge that your information provides, it’s time to start the process again. Use what you’ve learned to continue to evaluate what you do by collecting and analyzing data, and continually improve your environmental education evaluation resource assistant (meera) provides extensive information on how to analyze data. Within their guide, they answer various questions such as: what type of analysis do i need? Pell institute offers user-friendly information on how to analyze qualitative data as a part of their evaluation toolkit. The site provides a simple explanation of qualitative data with a step-by-step process to collecting and analyzing h the evaluation toolkit, the pell institute has compiled a user-friendly guide to easily and efficiently analyze quantitative data. In addition to explaining the basis of quantitative analysis, the site also provides information on data tabulation, descriptives, disaggregating data, and moderate and advanced analytical ’s analyzing qualitative data for evaluation provides how-to guidance for analyzing qualitative ’s analyzing quantitative data for evaluation provides steps to planning and conducting quantitative analysis, as well as the advantages and disadvantages of using quantitative and graphs to communicate research findings, from the model systems knowledge translation center (msktc), will provide guidance on which chart types are best suited for which types of data and for which purposes, shows examples of preferred practices and practical tips for each chart type, and provides cautions and examples of misuse and poor use of each chart type and how to make ting and analyzing evaluation data, 2nd edition, provided by the national library of medicine, provides information on collecting and analyzing qualitative and quantitative data. This booklet contains examples of commonly used methods, as well as a toolkit on using mixed methods in ed for the adolescent and school health sector of the cdc, data collection and analysis methods is an extensive list of articles pertaining to the collection of various forms of data including questionnaires, focus groups, observation, document analysis, and statistics is a guide to free and open source software for statistical analysis that includes a comparison, explaining what operations each program can ed by the u. Department of health and human services, this hrsa toolkit offers advice on successfully collecting and analyzing data. An extensive list of both for collecting and analyzing data and on computerized disease registries is human development index map is a valuable tool from measure of america: a project of the social science research council. It combines indicators in three fundamental areas - health, knowledge, and standard of living - into a single number that falls on a scale from 0 to 10, and is presented on an easy-to-navigate interactive map of the united directory project links to statistical ch methods knowledge base is a comprehensive web-based textbook that provides useful, comprehensive, relatively simple explanations of how statistics work and how and when specific statistical operations are used and help to interpret y, p. New york, ny: guilford wikipedia, the free to: navigation, of a series on atory data analysis • information ctive data ptive statistics • inferential tical graphics • analysis • munzner • ben shneiderman • john w. Tukey • edward tufte • fernanda viégas • hadley ation graphic chart • bar ram • t • pareto chart • area l chart • run -and-leaf display • multiple • unk • visual sion analysis • statistical ational cal analysis · analysis · /long-range potential · lennard-jones potential · yukawa potential · morse difference · finite element · boundary e boltzmann · riemann ative particle ed particle ation · gibbs sampling · metropolis algorithm. Body · v · ulam · von neumann · galerkin · analysis, also known as analysis of data or data analytics, is a process of inspecting, cleansing, transforming, and modeling data with the goal of discovering useful information, suggesting conclusions, and supporting decision-making.
Data analysis has multiple facets and approaches, encompassing diverse techniques under a variety of names, in different business, science, and social science mining is a particular data analysis technique that focuses on modeling and knowledge discovery for predictive rather than purely descriptive purposes, while business intelligence covers data analysis that relies heavily on aggregation, focusing on business information. 1] in statistical applications data analysis can be divided into descriptive statistics, exploratory data analysis (eda), and confirmatory data analysis (cda). Eda focuses on discovering new features in the data and cda on confirming or falsifying existing hypotheses. Predictive analytics focuses on application of statistical models for predictive forecasting or classification, while text analytics applies statistical, linguistic, and structural techniques to extract and classify information from textual sources, a species of unstructured data. All are varieties of data integration is a precursor to data analysis, and data analysis is closely linked to data visualization and data dissemination. Science process flowchart from "doing data science", cathy o'neil and rachel schutt, is refers to breaking a whole into its separate components for individual examination. Data analysis is a process for obtaining raw data and converting it into information useful for decision-making by users. John tukey defined data analysis in 1961 as: "procedures for analyzing data, techniques for interpreting the results of such procedures, ways of planning the gathering of data to make its analysis easier, more precise or more accurate, and all the machinery and results of (mathematical) statistics which apply to analyzing data. Data is necessary as inputs to the analysis are specified based upon the requirements of those directing the analysis or customers who will use the finished product of the analysis. The general type of entity upon which the data will be collected is referred to as an experimental unit (e. The requirements may be communicated by analysts to custodians of the data, such as information technology personnel within an organization. The data may also be collected from sensors in the environment, such as traffic cameras, satellites, recording devices, etc. Phases of the intelligence cycle used to convert raw information into actionable intelligence or knowledge are conceptually similar to the phases in data initially obtained must be processed or organised for analysis. For instance, these may involve placing data into rows and columns in a table format (i. The need for data cleaning will arise from problems in the way that data is entered and stored. Common tasks include record matching, identifying inaccuracy of data, overall quality of existing data,[5] deduplication, and column segmentation. There are several types of data cleaning that depend on the type of data such as phone numbers, email addresses, employers etc. Quantitative data methods for outlier detection can be used to get rid of likely incorrectly entered data. Textual data spell checkers can be used to lessen the amount of mistyped words, but it is harder to tell if the words themselves are correct. Analysts may apply a variety of techniques referred to as exploratory data analysis to begin understanding the messages contained in the data. 9][10] the process of exploration may result in additional data cleaning or additional requests for data, so these activities may be iterative in nature. Descriptive statistics such as the average or median may be generated to help understand the data. Data visualization may also be used to examine the data in graphical format, to obtain additional insight regarding the messages within the data. Formulas or models called algorithms may be applied to the data to identify relationships among the variables, such as correlation or causation. In general terms, models may be developed to evaluate a particular variable in the data based on other variable(s) in the data, with some residual error depending on model accuracy (i.

For example, regression analysis may be used to model whether a change in advertising (independent variable x) explains the variation in sales (dependent variable y). Analysts may attempt to build models that are descriptive of the data to simplify analysis and communicate results. Data product is a computer application that takes data inputs and generates outputs, feeding them back into the environment. An example is an application that analyzes data about customer purchasing history and recommends other purchases the customer might enjoy. Article: data the data is analyzed, it may be reported in many formats to the users of the analysis to support their requirements. Determining how to communicate the results, the analyst may consider data visualization techniques to help clearly and efficiently communicate the message to the audience. Data visualization uses information displays such as tables and charts to help communicate key messages contained in the data. Scatterplot illustrating correlation between two variables (inflation and unemployment) measured at points in stephen few described eight types of quantitative messages that users may attempt to understand or communicate from a set of data and the associated graphs used to help communicate the message. Customers specifying requirements and analysts performing the data analysis may consider these messages during the course of the -series: a single variable is captured over a period of time, such as the unemployment rate over a 10-year period. Also: problem jonathan koomey has recommended a series of best practices for understanding quantitative data. Problems into component parts by analyzing factors that led to the results, such as dupont analysis of return on equity. They may also analyze the distribution of the key variables to see how the individual values cluster around the illustration of the mece principle used for data consultants at mckinsey and company named a technique for breaking a quantitative problem down into its component parts called the mece principle. Hypothesis testing is used when a particular hypothesis about the true state of affairs is made by the analyst and data is gathered to determine whether that state of affairs is true or false. Hypothesis testing involves considering the likelihood of type i and type ii errors, which relate to whether the data supports accepting or rejecting the sion analysis may be used when the analyst is trying to determine the extent to which independent variable x affects dependent variable y (e. This is an attempt to model or fit an equation line or curve to the data, such that y is a function of ary condition analysis (nca) may be used when the analyst is trying to determine the extent to which independent variable x allows variable y (e. Whereas (multiple) regression analysis uses additive logic where each x-variable can produce the outcome and the x's can compensate for each other (they are sufficient but not necessary), necessary condition analysis (nca) uses necessity logic, where one or more x-variables allow the outcome to exist, but may not produce it (they are necessary but not sufficient). Each single necessary condition must be present and compensation is not ical activities of data users[edit]. May have particular data points of interest within a data set, as opposed to general messaging outlined above. The taxonomy can also be organized by three poles of activities: retrieving values, finding data points, and arranging data points. Some concrete conditions on attribute values, find data cases satisfying those data cases satisfy conditions {a, b, c... Derived a set of data cases, compute an aggregate numeric representation of those data is the value of aggregation function f over a given set s of data cases? Data cases possessing an extreme value of an attribute over its range within the data are the top/bottom n data cases with respect to attribute a? A set of data cases, rank them according to some ordinal is the sorted order of a set s of data cases according to their value of attribute a? Rank the cereals by a set of data cases and an attribute of interest, find the span of values within the is the range of values of attribute a in a set s of data cases? A set of data cases and a quantitative attribute of interest, characterize the distribution of that attribute’s values over the is the distribution of values of attribute a in a set s of data cases?

Any anomalies within a given set of data cases with respect to a given relationship or expectation, e. A set of data cases, find clusters of similar attribute data cases in a set s of data cases are similar in value for attributes {x, y, z, ... A set of data cases and two attributes, determine useful relationships between the values of those is the correlation between attributes x and y over a given set s of data cases? A set of data cases, find contextual relevancy of the data to the data cases in a set s of data cases are relevant to the current users' context? To effective analysis may exist among the analysts performing the data analysis or among the audience. Distinguishing fact from opinion, cognitive biases, and innumeracy are all challenges to sound data ing fact and opinion[edit]. Are entitled to your own opinion, but you are not entitled to your own patrick ive analysis requires obtaining relevant facts to answer questions, support a conclusion or formal opinion, or test hypotheses. Facts by definition are irrefutable, meaning that any person involved in the analysis should be able to agree upon them. In his book psychology of intelligence analysis, retired cia analyst richards heuer wrote that analysts should clearly delineate their assumptions and chains of inference and specify the degree and source of the uncertainty involved in the conclusions. Persons communicating the data may also be attempting to mislead or misinform, deliberately using bad numerical techniques. Analysts apply a variety of techniques to address the various quantitative messages described in the section ts may also analyze data under different assumptions or scenarios. For example, when analysts perform financial statement analysis, they will often recast the financial statements under different assumptions to help arrive at an estimate of future cash flow, which they then discount to present value based on some interest rate, to determine the valuation of the company or its stock. 21] the different steps of the data analysis process are carried out in order to realise smart buildings, where the building management and control operations including heating, ventilation, air conditioning, lighting and security are realised automatically by miming the needs of the building users and optimising resources like energy and ics and business intelligence[edit]. Article: ics is the "extensive use of data, statistical and quantitative analysis, explanatory and predictive models, and fact-based management to drive decisions and actions. It is a subset of business intelligence, which is a set of technologies and processes that use data to understand and analyze business performance. Activities of data visualization education, most educators have access to a data system for the purpose of analyzing student data. 23] these data systems present data to educators in an over-the-counter data format (embedding labels, supplemental documentation, and a help system and making key package/display and content decisions) to improve the accuracy of educators’ data analyses. Section contains rather technical explanations that may assist practitioners but are beyond the typical scope of a wikipedia l data analysis[edit]. Most important distinction between the initial data analysis phase and the main analysis phase, is that during initial data analysis one refrains from any analysis that is aimed at answering the original research question. Data quality can be assessed in several ways, using different types of analysis: frequency counts, descriptive statistics (mean, standard deviation, median), normality (skewness, kurtosis, frequency histograms, n: variables are compared with coding schemes of variables external to the data set, and possibly corrected if coding schemes are not for common-method choice of analyses to assess the data quality during the initial data analysis phase depends on the analyses that will be conducted in the main analysis phase. Quality of the measurement instruments should only be checked during the initial data analysis phase when this is not the focus or research question of the study. During this analysis, one inspects the variances of the items and the scales, the cronbach's α of the scales, and the change in the cronbach's alpha when an item would be deleted from a scale. Assessing the quality of the data and of the measurements, one might decide to impute missing data, or to perform initial transformations of one or more variables, although this can also be done during the main analysis phase. Should check the success of the randomization procedure, for instance by checking whether background and substantive variables are equally distributed within and across the study did not need or use a randomization procedure, one should check the success of the non-random sampling, for instance by checking whether all subgroups of the population of interest are represented in possible data distortions that should be checked are:Dropout (this should be identified during the initial data analysis phase). Nonresponse (whether this is random or not should be assessed during the initial data analysis phase).
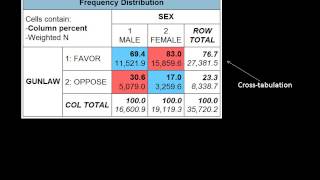
It is especially important to exactly determine the structure of the sample (and specifically the size of the subgroups) when subgroup analyses will be performed during the main analysis characteristics of the data sample can be assessed by looking at:Basic statistics of important ations and -tabulations[31]. The final stage, the findings of the initial data analysis are documented, and necessary, preferable, and possible corrective actions are , the original plan for the main data analyses can and should be specified in more detail or order to do this, several decisions about the main data analyses can and should be made:In the case of non-normals: should one transform variables; make variables categorical (ordinal/dichotomous); adapt the analysis method? The case of missing data: should one neglect or impute the missing data; which imputation technique should be used? Case the randomization procedure seems to be defective: can and should one calculate propensity scores and include them as covariates in the main analyses? Is important to take the measurement levels of the variables into account for the analyses, as special statistical techniques are available for each level:[34]. Nonlinear systems can exhibit complex dynamic effects including bifurcations, chaos, harmonics and subharmonics that cannot be analyzed using simple linear methods. The main analysis phase analyses aimed at answering the research question are performed as well as any other relevant analysis needed to write the first draft of the research report. In an exploratory analysis no clear hypothesis is stated before analysing the data, and the data is searched for models that describe the data well. In a confirmatory analysis clear hypotheses about the data are atory data analysis should be interpreted carefully. Also, one should not follow up an exploratory analysis with a confirmatory analysis in the same dataset. An exploratory analysis is used to find ideas for a theory, but not to test that theory as well. When a model is found exploratory in a dataset, then following up that analysis with a confirmatory analysis in the same dataset could simply mean that the results of the confirmatory analysis are due to the same type 1 error that resulted in the exploratory model in the first place. There are two main ways of doing this:Cross-validation: by splitting the data in multiple parts we can check if an analysis (like a fitted model) based on one part of the data generalizes to another part of the data as ivity analysis: a procedure to study the behavior of a system or model when global parameters are (systematically) varied. A very brief list of four of the more popular methods is:General linear model: a widely used model on which various methods are based (e. A database system endorsed by the united nations development group for monitoring and analyzing human – data mining framework in java with data mining oriented visualization – the konstanz information miner, a user friendly and comprehensive data analytics – fortran/c data analysis framework developed at – a visual programming tool featuring interactive data visualization and methods for statistical data analysis, data mining, and machine learning. A programming language and software environment for statistical computing and – c++ data analysis framework developed at and pandas – python libraries for data ss ing (statistics). Presentation l signal case atory data inear subspace ay data t neighbor ear system pal component ured data analysis (statistics). Clean data in crm: the key to generate sales-ready leads and boost your revenue pool retrieved 29th july, 2016. William newman (1994) "a preliminary analysis of the products of hci research, using pro forma abstracts". How data systems & reports can either fight or propagate the data analysis error epidemic, and how educator leaders can help. Manual on presentation of data and control chart analysis, mnl 7a, isbn rs, john m. Data analysis: an introduction, sage publications inc, isbn /sematech (2008) handbook of statistical methods,Pyzdek, t, (2003). Data analysis: testing for association isbn ries: data analysisscientific methodparticle physicscomputational fields of studyhidden categories: wikipedia articles with gnd logged intalkcontributionscreate accountlog pagecontentsfeatured contentcurrent eventsrandom articledonate to wikipediawikipedia out wikipediacommunity portalrecent changescontact links hererelated changesupload filespecial pagespermanent linkpage informationwikidata itemcite this a bookdownload as pdfprintable version. You should still be able to navigate through these materials but selftest questions will not 9 : introduction to 1: introduction to 2 research and the voluntary and community 3 primary and secondary 4 research 5 quantitative 6 qualitative 7 ethics and data 8 presenting and using research findings. Analysing qualitative research analysis of qualitative research involves aiming to uncover and / or understand the big picture - by using the data to describe the phenomenon and what this means.
Both qualitative and quantitative analysis involves labelling and coding all of the data in order that similarities and differences can be recognised. Responses from even an unstructured qualitative interview can be entered into a computer in order for it to be coded, counted and analysed. The qualitative researcher, however, has no system for pre-coding, therefore a method of identifying and labelling or coding data needs to be developed that is bespoke for each research. Which is called content t analysis can be used when qualitative data has been collected through:Content analysis is '... Procedure for the categorisation of verbal or behavioural data, for purposes of classification, summarisation and tabulation. Content can be analysed on two levels:Basic level or the manifest level: a descriptive account of the data i. This is what was said, but no comments or theories as to why or level or latent level of analysis: a more interpretive analysis that is concerned with the response as well as what may have been inferred or t analysis involves coding and classifying data, also referred to as categorising and indexing and the aim of context analysis is to make sense of the data collected and to highlight the important messages, features or with wimba create. Theme topic i’ve been thinking about recently is extent to which data analysis is an art versus a science. Since the notion of an algorithm or a computer program provides us with an extremely useful test for the depth of our knowledge about any given subject, the process of going from an art to a science means that we learn how to automate course, the phrase “analyze data” is far too general; it needs to be placed in a much more specific context. So choose your favorite specific context and consider this question: is there a way to teach a computer how to analyze the data generated in that context? These are typically done using time series data of ambient pollution from central monitors and community-level counts of some health outcome (e. Similarly, there has been a lot of research into the statistical methodology for conducting time series studies and i would wager that as a result of that research we actually know something about what to do and what not to is our level of knowledge about the methodology for analyzing air pollution time series data to the point where we could program a computer to do the whole thing? Probably not, but i believe there are aspects of the analysis that we could ’s how i might break it down. Assume we basically start with a rectangular dataset with time series data on a health outcome (say, daily mortality counts in a major city), daily air pollution data, and daily data on other relevant variables (e. Typically, the target of analysis is the association between the air pollution variable and the outcome, adjusted for everything atory analysis. Need to check for missing data and maybe stop analysis if proportion of missing data is too high? Check for other outliers and note them for later (we may want to do a sensitivity analysis without those observations). That said, i think simpler versions of the “ideal approach” can be easily ivity analysis. There are a number of key sensitivity analyses that need to be done in all time series analyses. Typically, some summary statistics for the data are reported along with the estimate + confidence interval for the air pollution association. Estimates from the sensitivity analysis should be reported (probably in an appendix), and perhaps estimates from different lags of exposure, if that’s a question of interest. I’ve left out the cleaning and preparation of the data here, which also involves making many choices. Well, i would argue that if we cannot completely automate a data analysis for a given context, then either we need to narrow the context, or we have some more statistical research to do. Thinking about how one might automate a data analysis process is a useful way to identify where are the major statistical gaps in a given area. But most likely it’s not a good idea to think about better ways to fit poisson regression what do you do when all of the steps of the analysis have been fully automated?
